

Como o Google funciona? Antes de elaborar estratégias de SEO ou Links Patrocinados, é necessário entender o buscador. Em todo mecanismo de busca encontramos 3 componentes principais: o crawler, o índice e a interface de busca e software de relevância.
? Crawler

Um crawler web é um programa de computador que vasculha a internet de forma sistemática e automatizada. Também são conhecidos como robôs web ou spiders. O crawler funciona recebendo uma URL inicial. Ao carregar a página da primeira URL, ele extrai as outras presentes na página e segue cada uma delas, repetindo o processo. Como a internet é praticamente toda interligada por links, a partir de poucas URLs um crawler consegue navegar por uma vasta quantidade de páginas. Normalmente, eles são construídos de forma a não passar mais de uma vez pela mesma página e feitos para trabalhar em paralelo, permitindo carregar várias páginas simultaneamente.
? Índice
A medida que o crawler carrega, as informações presentes em cada uma das páginas navegadas são armazenadas em índices. Porém, não basta simplesmente salvar o conteúdo de uma página web no índice, visto que é necessário saber como as informações estão presentes em cada uma dessas páginas ao se fazer uma busca.

Por exemplo, se queremos ter um índice com a quantidade de vezes que cada palavra aparece em uma página, precisamos armazenar a informação da seguinte forma:
1.
1. Separar todas as palavras presentes na página.
2. Para cada palavra, contar quantas vezes ela aparece repetida.
3. Armazenar cada palavra com o número de vezes que foi contado.
Com isso, ao pesquisarmos por uma determina palavra, podemos rapidamente descobrir em qual página ela aparece o maior número de vezes.
Atualmente, os índices que os mecanismos de busca utilizam possuem muito mais informações do que a quantidade de vezes em que uma palavra aparece. Informações sobre a estrutura da página, que indicam a relevância de um determinado trecho, são muito mais importantes de serem armazenados em um índice. Além disso, informações como URL, título da página e outros meta dados também são relevantes para os índices de indexação.
? Interface de busca e Software de Relevância
A interface do mecanismo de busca permite ao usuário entrar com os termos de pesquisa e ver os resultados encontrados, ordenados pelo software de relevância. Ao se digitar uma palavra no mecanismo de busca, a mesma é comparada com os resultados armazenados nos índices e, através de vários fatores, os resultados são exibidos para o usuário ordenados pela sua relevância.
No início dos mecanismos de busca, o principal fator para se determinar qual era a página mais relevante consistia em contar o número de vezes que a palavra buscada era empregada. Porém, isso logo se mostrou um problema para os mecanismos de busca, pois permitia aos criadores das páginas manipular facilmente a ordem dos resultados. Por exemplo, sabendo que a palavra “grátis” era um termo muito pesquisado, ao se desenvolver uma página, bastava acrescentar várias vezes a palavra “grátis” ao final da página para que esta aparecesse a mais usuários. Com o sistema de relevância PageRank, criado pelo Google, essa manipulação de resultados ficou obsoleta, já que a reputação do site passou a ser mais importante do que o número de vezes que um termo aparecia.
Como o Google Funciona
A tecnologia empregada pelo Google tornou-se o padrão para o mercado atual de mecanismos de busca. No entanto, os conceitos explicados aqui servem para qualquer mecanismo de busca moderno.
Googlebot
Todo mecanismo de busca possui um de crawler, e o do Google é conhecido como Googlebot. Cada vez que o Googlebot encontra uma nova URL, ele carrega esta página e armazena as informações no índice do Google, além de descobrir novas URLs para se visitar.
Porém, como as páginas podem ter o seu conteúdo atualizado, o Googlebot precisa visitar a mesma página em intervalos regulares de tempo para determinar se as informações de seu índice estão desatualizadas. Atualmente, o Googlebot é inteligente o suficiente para estimar com que frequência uma página é atualizada. Por exemplo, ele pode determinar se a página principal de um site de notícias, como o CNN.com, é atualizado frequentemente e, por isso, passa por ele várias vezes ao dia. Já em um página pessoal, ele pode passar uma única vez por mês, depois de perceber que a página quase nunca recebe atualizações. O PageRank, de uma página, como veremos no próximo tópico, também é um importante fator para determinar o número de vezes que o Googlebot visitará a página. Uma vez que o Googlebot carrega uma página, essas informações podem ser adicionadas ao índice em alguns segundos e ficarem disponíveis nos resultados mostrados aos usuários.
O Googlebot enxerga as páginas de uma forma muito diferente da que nós, usuários, enxergamos. Ele vê apenas o código HTML utilizado para gerar a sua página. Por isso uma das principais funções para melhorar o posicionamento das páginas é garantir que o Googlebot esteja enxergando o seu conteúdo corretamente.
Para que você possa ter uma ideia de como a sua página é vista por um crawler, você pode utilizar um browser de texto. O browser de texto mais popular é o Lynx, que apesar de ser um programa executado localmente, possui algumas versões on-line, como a disponível no endereço http://www.delorie.com/web/lynxview.html

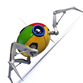
O crawler a verá de outra maneira:


Como o Google indexa as páginas
Para cada página que o Googlebot visita, as informações contidas no HTML são indexadas (ou seja, registradas no sistema do Google). No índice básico, é necessário saber em quais documentos estão presentes o termo que o usuário está buscando. O que o Google faz com cada página é separar cada palavra e armazenar em quais documentos essa palavra aparece.
Por exemplo: Quando você pesquisa por ‘Mecanismo de Busca‘ o índice sabe que a palavra “mecanismo” está presente nas páginas 1, 2, 30, 987, 1050 e 2400, e a palavra “busca” aparece nas páginas 1, 3, 55, 987 e 5562.
Portanto, as páginas 1 e 987 serão aquelas mostradas no resultado da busca, pois possuem todos os termos requisitados. Porém, a ordem em que essas páginas aparecem para o usuário depende de outro componente: o PageRank da página.
PageRank
Quando você faz uma busca no Google através do índice, é fácil determinar em quais páginas os termos pesquisados estão presentes. Porém, o que importa é saber quais dessas páginas são mais relevantes para o usuário.

Para resolver este problema, dois alunos de doutorado da Universidade de Stanford, Larry Page e Sergey Brin, se basearam em um conceito já existente nas publicações de artigos científicos. Para se determinar a importância de um determinado artigo, é comum contar a quantidade de outros artigos que citam o primeiro. Com isso, artigos que são mais citados por outros são considerados mais relevantes.
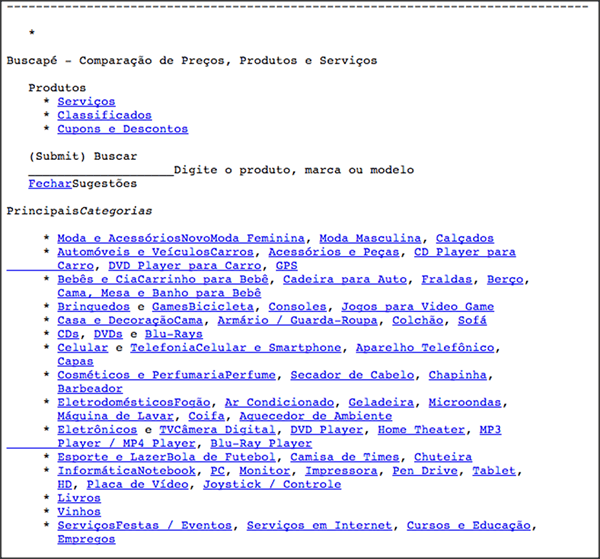
Larry Page e Sergey Brin utilizaram esse conceito de citações, porém usando os links entre as páginas da web para determinar a sua importância. Quando você pesquisa por “coca cola”, por exemplo, o que o Google faz é verificar, dentre todas as páginas indexadas que possuem os termos “coca” e “cola”, qual é a que possui maior quantidade de links vindo de outras páginas.
Além disso, essa contagem de links é recursiva. Então, se a página “A” possui 50 outras páginas apontando para ela e essa mesma página “A” possui um link apontando para a página “B”, então parte da reputação que a página “A” recebeu e é repassada para a página ‘B‘. Imagine isso sendo feito em todas as centenas de milhares de página indexadas pelo Google. Baseado nessa reputação, cada página recebe uma pontuação conhecida como PageRank. Esse valor é único por página, por isso, dentro de um mesmo domínio, temos páginas com PageRank diferentes.


Fonte: http://en.wikipedia.org/wiki/PageRank
É importante lembrar que a quantidade de links ligando as páginas é um fator importante para se determinar o PageRank, porém não é o único. Atualmente, o Google analisa mais de 200 componentes da página para se determinar o seu PageRank. No entanto, esses fatores e a importância que cada um exerce no PageRank costumam ser mantidos em segredo pelo Google.
Exibindo os Resultados
O termo técnico utilizado para denominar a página que exibe os resultados da busca é SERP (Search Engine Results Page), ou Página de Resultados do Mecanismo de Busca, em português. Basicamente, ela contém o título da página com uma descrição do conteúdo ou o texto relacionado com o termo buscado, além do link para a página.
Após determinar quais as páginas mais relevantes para o termo que você pesquisou, o Google ainda pode acrescentar uma série de outros links ao resultado:
? Sites com conteúdo local do usuário são promovidos nos resultados.
? Com a pesquisa universal, se o Google acha que notícias, produtos, vídeos, livros, locais ou outras pesquisas verticais são relevantes, então ele pode misturá-las diretamente entre os resultados da busca.
? Sites que o usuário visitou no passado podem ser promovidos no resultado.
? Se um termo começa a ser muito buscado por várias pessoas em um intervalo curto de tempo o Google pode dar preferência a páginas que foram atualizados recentemente.
? Várias páginas de um mesmo domínio podem ser agrupadas em um único resultado, formando um índice.